
我现在正在用 macOS Sequoia 的开发者预览版写这篇文章,用唯一的主力机装早期的预览版系统还挺冒险的,但窗口管理、备忘录更新这些小更新对我的诱惑挺大,实在没有忍住,就冲了。
发布会之前,Mark Gurman 早就把WWDC将要发布的 AI 相关内容透了个底掉,而苹果欲说还休的样子,让整个发布会的前面大半段显得格外无趣。一个个功能更新对苹果来说不过是屎上雕花,却无情地砸掉一个个中小开发者的饭碗(在此特别哀悼 1password、Moom、Mosaic、fantastic)。
而 Apple Intelligence 给人的直观感觉则像是在把 Mark Gurman 的播客转录成文字大纲照本宣科。没有惊喜,但人人都不会觉得事情仅此而已。
按照苹果官网的介绍,Apple Intelligence 由多个功能强大的生成模型组成,这些模型专门用于用户的日常任务,并可即时适应用户当前的活动,其中包括一个 ~30 亿参数的设备语言模型,以及一个更大的基于服务器的语言模型,可通过私有云计算在 Apple 芯片服务器上运行。
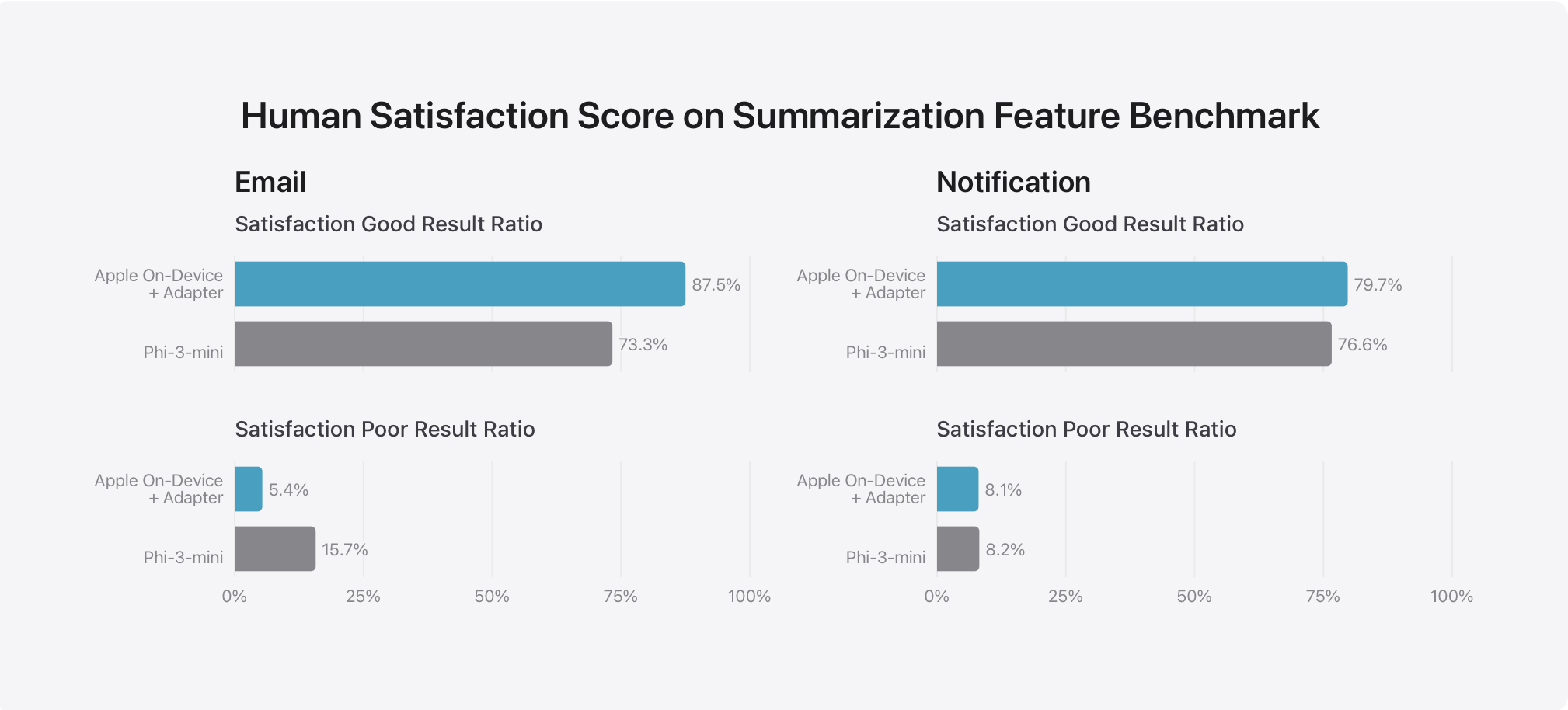
他们将自研模型与开源模型(Phi-3、Gemma、Mistral、DBRX)和类似规模的商业模型(GPT-3.5-Turbo、GPT-4-Turbo) 进行了比较,号称自研模型更受人工评分师的青睐。在此基准测试中,设备端模型(具有 ~3B 参数)的性能优于 Phi-3-mini、Mistral-7B 和 Gemma-7B 等大型模型。服务端模型与 DBRX-Instruct、Mixtral-8x22B 和 GPT-3.5-Turbo 相比具有优势,同时效率很高。
也就是说,用户发起的AI相关需求,苹果会优先使用端侧模型,其次是私有云的服务器端模型,最后才是调用外部模型接口(GPT-4O)。
于是可推导出两点:
- 苹果在当前状态下,并不是完全依赖外部AI服务商,换言之,使用GPT-4O和使用文心一言的体验差距可能没有想象中的大(先给自己一剂安慰剂)。
- 对于外部AI服务商,苹果至少说部分充当了一个分发者的角色,有可能会基于各种因素(合规、性价比、效果),调用多家外部服务。乐观点,国内上线时很可能同时对接文心一言、通义、豆包、kimi(再给自己一剂安慰剂)。
相对于其它模型依赖于用户主动输入信息,苹果将为AI提供系统级的服务,即便仅在端侧运行,可获得的信息资源也是碾压级别。于是我们可以在发布会上看到Siri可以跨应用调用信息,并理解用户个人背景。对 Apple Intelligence 来说,每台设备都是一个独立且可被用于训练的私有数据库。
如果你是一个笔记爱好者,我强烈建议你使用基于本地的笔记应用,比如Obsidian、比如备忘录,你不仅可以基于传统整理术去管理自己的笔记,还可以让 Apple Intelligence 从系统层面实现更丰富的“Notion Q&A”。
发表回复